-v2.png)
Introduction
Reinforcement Learning from Human Feedback is most commonly associated with the final training stages of large language models like ChatGPT or Claude. It’s what helps these models better align with human values, making them more helpful, safe, and trustworthy. But RLHF isn't limited to chatbots or text generation. In fact, the idea of using human preferences to shape agent behavior goes back to much earlier experiments in training AI agents for games.
One of the foundational papers in this area is Deep Reinforcement Learning from Human Preferences [1], where researchers trained agents using human comparisons of short video clips instead of using the built-in reward function. We used a similar approach to train an agent, but used a different way to collect feedback.
Instead of relying on contractors for human feedback, which are relatively expensive and hard to find, we used Rapidata's core technology to solve this problem. It allowed us to instantaneously reach a wide pool of annotators, proving that Rapidata's human feedback can be used to efficiently train reinforcement learning agents.
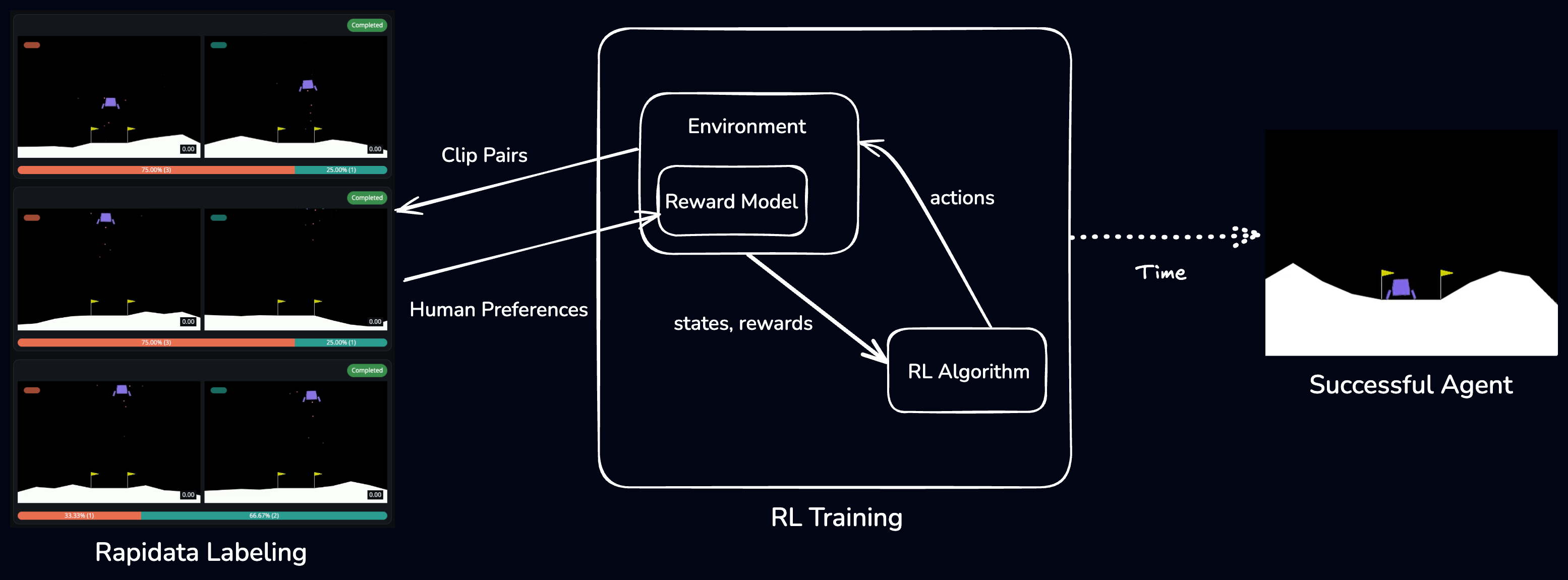
Training scheme illustration
In this post, we’ll walk you through our setup, how we used Rapidata, and what we observed during training.
Setup
Our agent was trained to solve the LunarLander-v3 environment from OpenAI Gymnasium. In this task, a lunar lander starts at the top of the screen and must land safely on a designated landing pad. Terrain varies between episodes, and a random force is applied at the start of each episode.
LunarLander-v3 Gymnasium environment comes with a reward function that is calculated using the current state of the lunar lander. It was probably hand-engineered by the creator of the environment. The reward function punishes for values of position, speed, angle and other state parameters which are less likely to lead to a successfull landing. Our training doesn't use this reward function in any way and is completely based on the human feedback.
Here’s an overview of our technical setup:
- We used a PPO (Proximal Policy Optimization) implementation from CleanRL [2].
- The reward model loss which used human feedback was implemented from scratch, following the method from Deep Reinforcement Learning from Human Preferences [1].
- We initialized the reward model with 500 human-labeled clip comparisons and added 200 more after every 500,000 training steps.
- In total, we trained the agent for 10 million steps, using 4,300 labels from human feedback.
Using the Rapidata Human Feedback
To collect human feedback, we presented users with pairs of short clips showing the agent attempting to land. We asked them to pick the clip that better matched the intended goal of the task. The prompt shown to annotators was:
Which rocket is more likely to land on the legs slowly and without being tilted in flight? Ideally, it should land between the flags and stop.
Here is an example pair of clips:
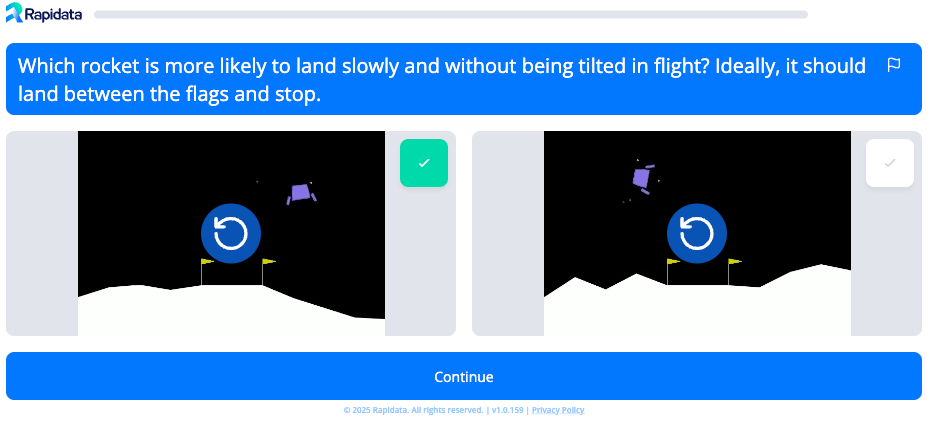
To help annotators better understand the game, we created a set of seven clip pairs to illustrate which behaviors are better in some simple cases.
We used it to measure the progress of annotators in determining the right behavior. We first trained the annotators and, as soon as they gained a good level of mastery, we started giving them real tasks.
Rapidata API Implementation Details
From the Rapidata tooling perspective, we first created a validation set with seven clip pairs. Then we set this validation set to update a custom user score dimension to keep track of the annotators progress. To give the right type of task to people (either validation or an actual task) depending on their mastery, we used a ConditionalValidationSelection. The selection we used is very similar to this:
selections=[
ConditionalValidationSelection(
validation_set_id=VALIDATION_ID,
thresholds = [0, 0.6, 0.75],
chances = [1, 1, 1],
rapid_counts = [3, 2, 1],
dimension="lunar_lander"
),
LabelingSelection(2),
]Results
We tracked the agent’s progress during training and created a video showing how its behavior evolved:
After the end of training, the agent consistently lands slowly. If we were to use the built-in reward we would probably get a a behaviour looking more like after 75%, than after 100% because the use of the main engine is discouraged with the built-in reward. By contrast, human feedback encouraged safer landings, likely because the prompt explicitly mentioned "land on the legs slowly". This is consistent with findings from the original paper [1], where human preferences didn't always align with the built-in reward.
Shaping the Reward Function
Let’s take a closer look at how human feedback influenced the learned reward model
Landing slowly
The hardest part of landing is touching the ground. On the one hand, it shouldn't be too fast, then the lunar lander would crash, on the other hand it shouldn't be too slow, because the lander wouldn't land and would just end up hovering above the ground. Here's the heatmap of the reward that an agent would receive for the use of the main engine when flying down.
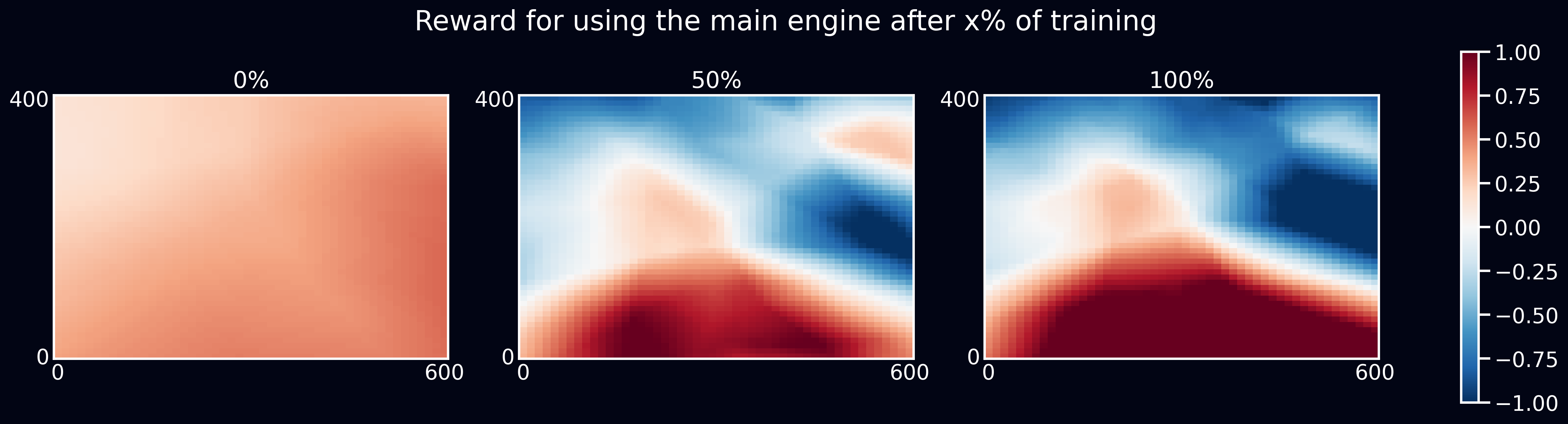
The learned reward for the use of the main engine when the lander is falling (negative vertical speed).
The model learned to reward the use of the main engine when close to the ground. Using the main engine at that point would save the lunar lander from crashing. We also see that the reward grew from 50% to 100% of training which explains the more cautious behaviour in the end.
Compensating the initial force
To successfully land, the lunar lander should be able to deal with the initial force applied to it. Let's see what happens with the reward when the lunar lander is pushed diagonally to the right at the beginning of training.
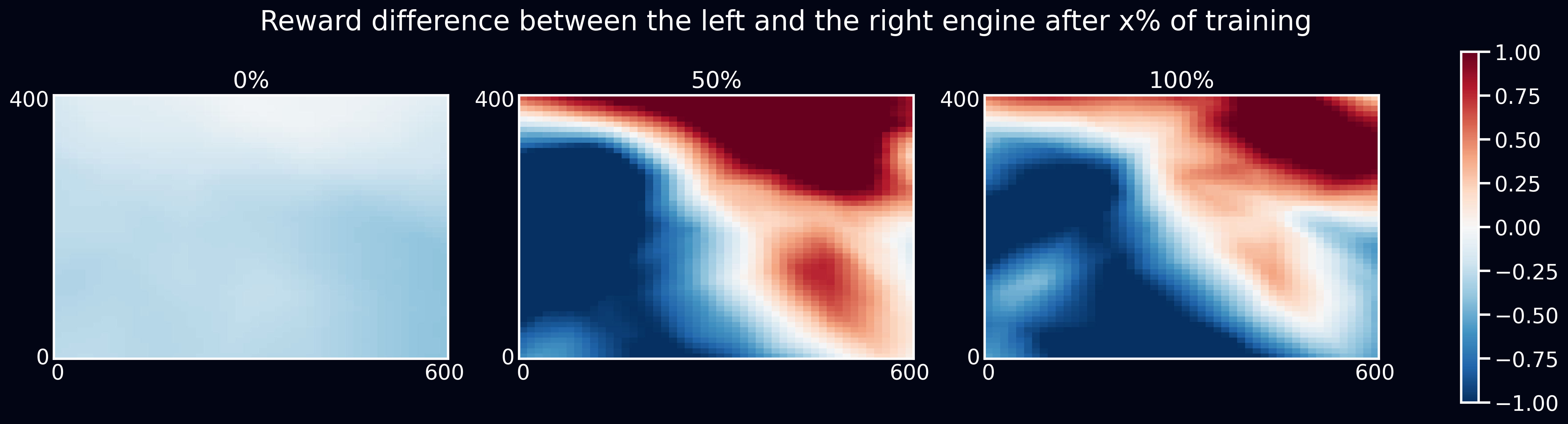
The difference in reward between using the left and right engines when the lander is flying diagonally toward the bottom-right (positive x speed, negative y speed).
Notice that we consider the reward difference between the left and the right engine and not just the reward for the left one. This is because the reward for the left engine doesn't tell much on its own. For example, both left and right engines can get high reward and then the lunar lander will learn not to move to sides. While we want to show that it more actively uses the left engine to compensate for the push.
The reward difference shows that the agent is motivated to compensate for the diagonal force applied at spawn by using the left engine. The lunar lander follows the reward signal and learns to use the left engine more actively after the initial push. Here is an example of this behavior:
Lunar Lander compensating for the initial diagonal push.
Conclusion
To successfully train an agent, we need to know which behaviors should be incentivized and which should be punished. To quantitatively estimate agent states and actions, we use a reward model.
For some problems, including LunarLander-v3, it is possible to come up with an explicit reward function. However, when it comes to complicated tasks like making chatbots more helpful or aligning generated images with prompts, we need neural networks capable of learning non-obvious patterns from data.
In this blog post, we showed that it's possible to train a good reward model for LunarLander-v3 based on human preferences collected through Rapidata. This suggests that the same approach could be applied to more complex tasks like image and text alignment, an area we are now actively exploring.
References
[1]: Christiano et al. (2017). Deep reinforcement learning from human preferences https://arxiv.org/abs/1706.03741
[2]: CleanRL https://github.com/vwxyzjn/cleanrl
